

Hello there!
Today I'm writing up my trials and tribulations of implementing caching in GitHub Actions, a classic "this will only be a 5 minute job" that turned into days of my life! 📆
A quick overview 🔍
At Prosopo, we have a single monorepo which has a main branch. We branch off the main branch to build new features, then pull request the feature back into the main branch. The pull request has to pass a bunch of workflows before being merged. Pretty standard.
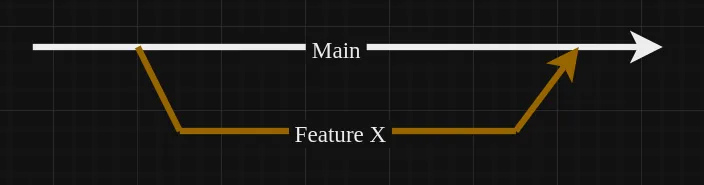
The beginning 🕘
We've been using GitHub Actions for years to automate our continuous integration and deployment pipelines. All had been going well, but the number of packages had grown to ~30. Add into the mix some of these packages being written in rust and our build times were creeping into the 20 minute zone - not good. It was so bad I ended up context switching to another task whilst waiting for workflows to complete!
We were building everything from scratch on each workflow run. Immediately, I realised that this was great for testing the build process, but really poor for performance when only 1 line of code has changed in 1 package and all ~30 packages are being rebuilt from scratch!
The bright idea 💡
I thought to myself "well let's cache the build output, that'll surely speed things up". After some reading of the GitHub Actions docs, I felt comfortable utilising GitHub Actions' built-in caching mechanism in our workflows. This was not a quick fix!
Gotcha! 😖
Nothing is ever simple. GitHub Actions (for some reason) adds a bunch of rules to caching which are not particularly well advertised:
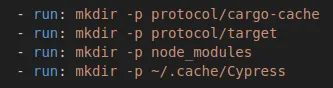
Cached directories must exist before restoring a cache 🤯
Ridiculous! If a cached directory does not exist ahead of restoring a cache, the whole cache restore job silently fails. It took me ages to realise what was going on. So now I run a mkdir -p command for every cached directory before restoring the cache.
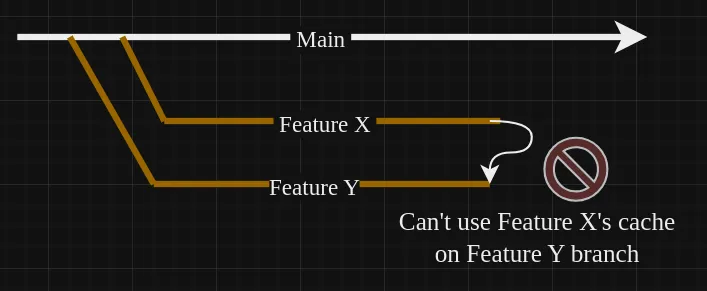
Caches cannot be shared between branches 😑
Naff. Just naff. I was hung up on this for quite a while. Because of this rule, caching is only helpful for incremental builds (i.e. do a build, change something, build again from the first build's output to speed things up). This is nice, but if I have two very similar branches, e.g. branch A and B, branch B cannot borrow the build output from branch A to speed up the build. Keep reading to find out how I got around this.
Caches can be inherited from parent branches 💥
Interesting. So if I make branch A and B inherit from a parent branch, say branch C, then build branch C and cache the output, branch A and B would have access to that cache.
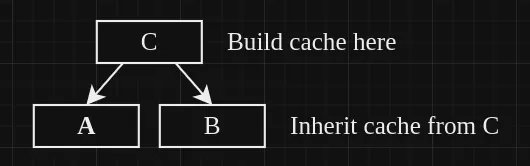
I really took advantage of this rule. Everything inherits from the main branch in our repo. If I build the cache on the main branch, every single branch in the repo has access to the cache. Brilliant, and works well when sharing caches between branches.
Caches are immutable 🙃
Once a cache is created, it cannot be updated. Silly, in my opinion. So picture this: I build a cache on the main branch, great. I merge in a PR for a new feature. I now need to build the main branch with the new feature and save the build output to the cache - except I can't, because I can't overwrite the cache. Urgh.
If you google this, you'll find a lot of people telling you to just delete the cache and save it again. This works, but there's a brief time between deleting the cache and saving a fresh one, which is undesirable for large caches. For example, our cache is 1.3Gb, so it takes a couple of minutes to tarball up the cache in GitHub Actions. That means there's a ~2 minute window where workflows have no cache to build from, leading to those 20 minute workflow times again! I'm sure you're sitting there thinking "well that can't happen that frequently, so surely it's fine", but it happens much more than you would think. Every PR that gets merged has this 2 minute window. Every commit pushed up to an open PR runs CICD workflows which rely on this cache. We have ~10 open PRs being actively worked on at a time (but this fluctates highly!). You can imagine how the opportunity to hit this 2 minute window rises and rises!
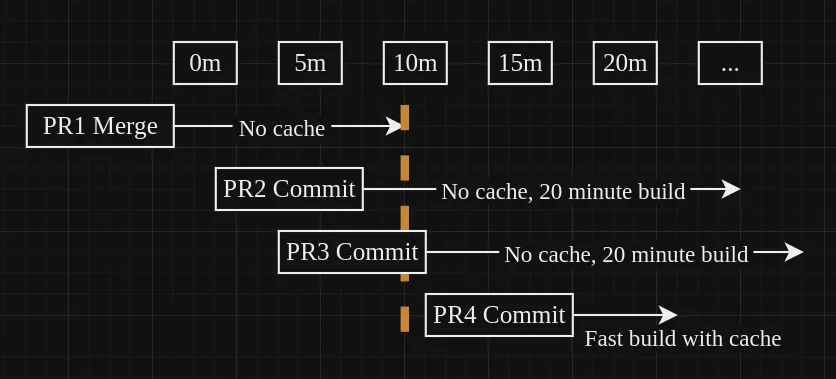
So to work around this, I used wildcard cache names. This is a mechanism in GitHub Actions which says if a cache's name ends in a -, treat the name as a regex selection ending in a wildcard. For example, abc-def- would match abc-def-1, abc-def-2, abc-def-i-cant-believe-how-much-time-i-spent-working-this-out, etc. It uses the most recent one, which is neat.
I've setup the monorepo to work with a single cache built on the main branch. I've named this cache project-cache-${{ runner.os }}-${{ runner.arch }}-${{ github.run_id }}-${{ github.run_attempt }}. This ensures that caches are specific to the OS and architecture and stamped with the run id and attempt to differentiate them from the cache of other workflows/runs. For example, say I've merged in feature A. A cache would be built for that commit. Then say I merge in feature B. Another cache would be built for that commit. We need to be able to tell these apart, hence the usage of run id and attempt.
So now caches are saved with a known prefix and an unknown suffix (the run id and attempt). When it comes to restoring a cache, we simply specify the cache name as project-cache-${{ runner.os }}-${{ runner.arch }}- and GitHub will find us the most recent cache matching that name. Nice!
Wait: another gotcha! GitHub has a cache limit of 10Gb, which is fair enough, there's only so much node_modules they want stuffing up their servers 😂. Once you hit the 10Gb limit, GitHub will automatically evict the oldest caches until back under 10Gb. Now imagine you've got a project which has two caches. If the first cache is updated frequently, the 10Gb limit will be hit at some point. However, because the second cache is not updated as frequently it may be the oldest cache and thus be evicted by GitHub, rendering your second cache unavailable and useless!
Luckily, we don't have a second cache right now, but I wanted to future proof this. So I came up with an idea to evict old caches myself rather than leaving it down to GitHub. This would allow me to evict old caches for a specific cache, avoiding the case where a frequent cache clogs up the cache storage on GitHub.
So first we save the cache:
- name: Save cache
uses: actions/cache/save@v3
if: always()
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}-${{ github.run_id }}-${{ github.run_attempt }}Which leaves us with >=2 caches: the one we just saved and 1 or more previous caches (should ideally be 1, but coding for flexibility here).
So next we'll evict all bar the latest cache (the one we just saved):
- name: Cleanup caches
if: always()
run: |
set +e; gh extension install actions/gh-actions-cache; set -e
REPO=${{ github.repository }}
echo "Fetching list of cache key"
cacheKeys=$(gh actions-cache list --sort created-at --order desc --limit 100 -R $REPO --key project-cache-${{ runner.os }}-${{ runner.arch }}- | cut -f 1 | tail -n +3)
echo caches to be removed:
echo ${cacheKeys}
set +e
for cacheKey in $cacheKeys
do
gh actions-cache delete $cacheKey -R $REPO --confirm
doneWe use a gh extension to fetch a list of caches matching our cache key. We then delete all bar the latest cache matching said key. This leaves us with the single cache we just built, all older caches (for this key) have been evicted. Any other caches (for other keys) will remain in GitHub as they were, so as long as you keep below the 10Gb limit you can have several caches all on the go at once! Note there is a minor overhead to this technique where for a short period there will be 2 caches, the old one and the new one. If this takes you over the 10Gb limit, GitHub may beat you to the eviction process and you'll have no say over what cache is evicted. Just something to keep in mind.
The solution in a nutshell 🥜
The above section jumped around a bit as I dumped / vented about my journey through GitHub Actions caches. So in this section, I'll lay out the workflows from start to finish:
After a PR has been merged into main, we run a workflow which builds everything and stores the build output in a cache:
name: post_pr
on:
push:
branches:
- 'main'
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: mkdir -p protocol/cargo-cache
- run: mkdir -p protocol/target
- run: mkdir -p node_modules
- run: mkdir -p ~/.cache/Cypress
# build the code here!
- name: Save cache
uses: actions/cache/save@v3
if: always()
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}This is run on push to main or manual run via GitHub (which is useful if you've had to clear the cache manually on GitHub and want to repopulate it).
Note that we don't restore the cache from previous builds as this would create a cache loop where you'll get weird artifacts from previous builds sticking around in your new cache. Over time, your cache will balloon in size and then hit the 10Gb GitHub limit. Guess how I found this out! 😖
For safety, we create the 4 directories that we are going to cache. This is to protect against the build process failing to create these directories, as the entire caching mechanism silently fails if your directories do not exist 🎉
The 4 directories: cargo-cache for rust, target as the output for rust, node_modules for js based packages and finally the cypress cache.
Then it builds the code (omitted for brevity) and saves the cache under the cache key.
Note that the cache is named under the OS and architecture of the system, so you can have different caches for different OS's and architectures! This is good practice 😄
Upon PR creation, our CICD workflows begin. We'll look at just the testing workflow for simplicity.
name: tests
on:
pull_request:
branches: [main]
workflow_dispatch:
jobs:
check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: mkdir -p protocol/cargo-cache
- run: mkdir -p protocol/target
- run: mkdir -p node_modules
- run: mkdir -p ~/.cache/Cypress
- name: Restore cache
uses: actions/cache/restore@v3
with:
path: |
protocol/cargo-cache
protocol/target
node_modules
~/.cache/Cypress
key: project-cache-${{ runner.os }}-${{ runner.arch }}
# build and test here!The testing workflow is triggered on a PR into main. It begins by making the cached directories, again because things silently fall apart otherwise! Then we restore the cache using a cache key wildcard, which will pick the latest cache which matches the key. We then do the build and testing.
Making things run smoothly 🏃
Make sure to make your workflows cancellable. This ensures that if something changes (e.g. a new commit) current workflows are abandoned and new ones are started. This works well for the post_pr workflow, as it prevents multiple cache creation events happening at the same time. In theory it's fine, they shouldn't conflict, but there's a slim chance you may end up with the cache from the older workflow than the newer one!
A plea to GitHub 🤞
Just let us use whatever cache for whatever we want. Any branch. It would be far simpler.
For our sanity, please mkdir a directory if it does not exist already for the cached directories. Or at least print an error!
Evicting caches based on the age / number of caches per cache key would also be super helpful.
Conclusion 📋
GitHub Actions caching is really cool and helpful, but will drive you insane if not careful.
Related Posts to GitHub Actions: Cache Chaos 🤯

TypeScript: Mapped Type Magic 🪄
Wed, 13 Mar 2024

Vite: How to handle `.node` files
Mon, 08 Apr 2024

Using Vite To Rebuild Local Dependencies in an NPM Workspace
Thu, 18 Apr 2024
TypeScript: Branded Types 🔧
Mon, 22 Apr 2024

It's time to drop ts-node 🌇
Wed, 26 Jun 2024
How to Test Your Ansible Playbooks Locally
Tue, 30 Jul 2024

How Does CAPTCHA Collect User Data? The Reality
Fri, 25 Apr 2025

Monorepo vs Multirepo Architecture: How to Decide?
Thu, 01 May 2025

Mastering Versioning: A Guide to Software Stability
Fri, 02 May 2025

Independent vs Locked Versioning in a Workspace
Sat, 03 May 2025

Streamlining Releases: Building Scalable CICD Pipelines with Changesets
Tue, 06 May 2025

PHP Views Package - Templating Made Easy with Blade and Model-Driven Approach
Mon, 19 May 2025
Reactive Frameworks Cheatsheet - React, Vue, Svelte and Angular
Mon, 19 May 2025

We cut our Mongo DB costs by 90% by moving to Hetzner
Wed, 12 Nov 2025